 第一次看别人写 Agent prompt,我也觉得像过家家。
第一次看别人写 Agent prompt,我也觉得像过家家。
「你是一个 20 年经验的资深专家。」
「你要严谨、主动、有洞察、站在用户视角思考。」
「你是 CEO Agent,你是 CTO Agent,你是 CMO Agent,你们先开会讨论。」
这画面太熟了。像一群小孩把玩具摆成董事会,嘴里念着大人的词。
更难受的是,它经常真的没用。模型换了一套西装,说话更像咨询顾问,输出还是那堆软东西。语气更老练,判断没变硬;措辞更像专家,结果还是不能交付。
所以,先把这句话说死:大量 Agent 人设堆砌,确实就是角色扮演。
「你是世界顶级架构师」不是架构能力。
「你要有批判性思维」不是审查机制。
「你要主动推进」不是工作流。
「你要追求高质量」不是质量标准。
这些话的问题不是完全没效果,而是边界太软。它们只给了模型一个戏服,没有给它岗位说明书、权限表、工具箱、拒绝条件、验收线和事故处理预案。
但如果你因此得出结论:所有 Agent 规训都是 cosplay,那也太省事了。
这里先把定义说清楚。
如果你说的「调教 Agent」,只是给模型写人设、取角色名、设定性格,那大部分确实是 cosplay。
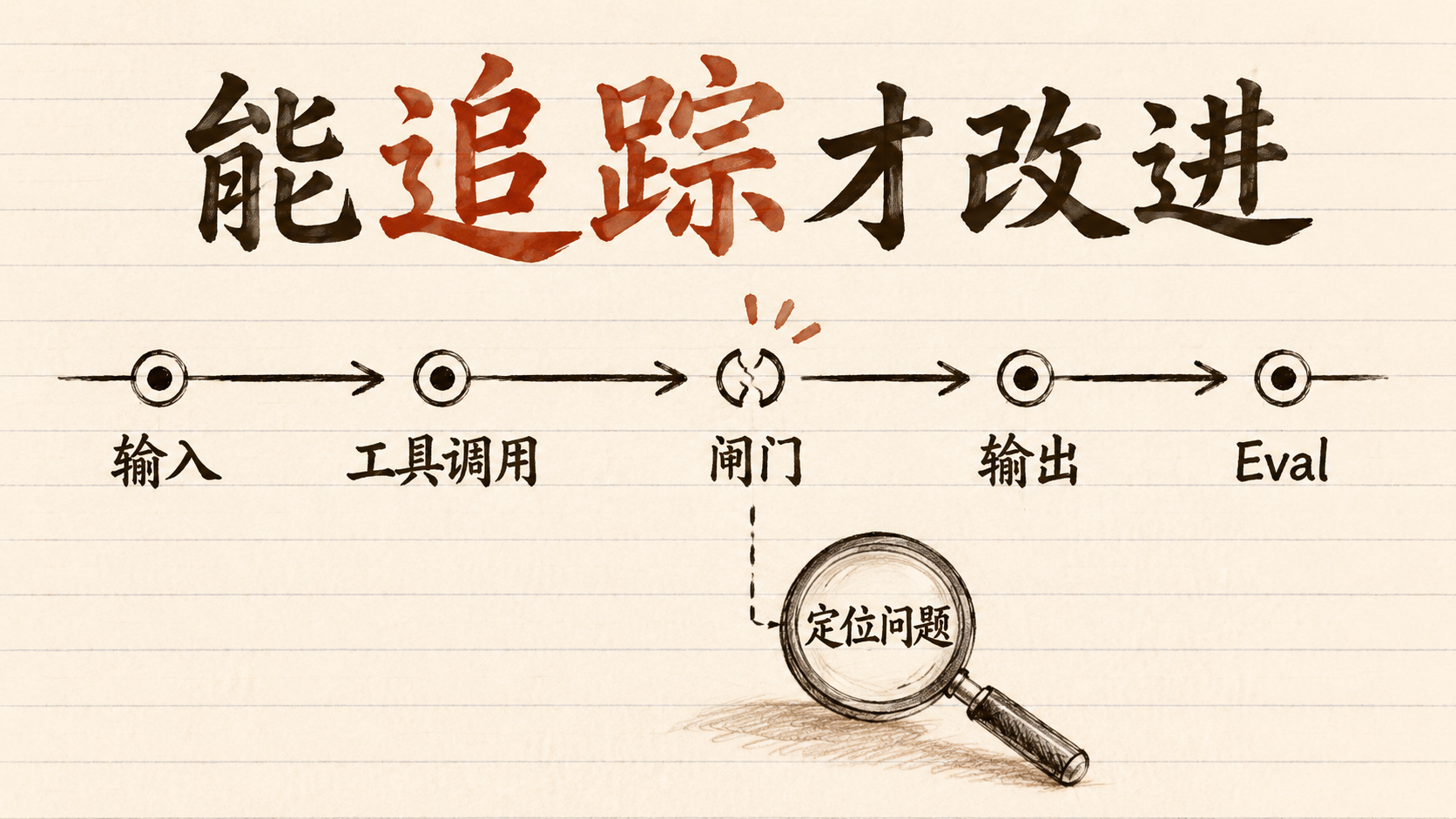
我说「不一定」,指的是更宽的工程化规训:输入、工具、权限、质量闸门、trace(过程追踪)和 eval(评估机制)。
如果你觉得后者应该叫工程,不该叫调教,那其实已经同意这篇文章的分界线了。
真正可笑的,不是 Agent 有人设。
真正可笑的是,很多公司的人类岗位也只有人设。
补洞与口号
你让员工「有 owner 意识」,跟你让 Agent「像专家一样思考」,指令本身都是模糊的。
区别当然有。
人类员工会补洞。他会看老板脸色、同事历史、公司气氛、过往事故,慢慢猜出「owner 意识」在你这里到底是什么意思。
这个机制不精确,也不可靠,但它确实存在。
Agent 没有。
或者更准确地说,Agent 会把你的废话执行成垃圾,然后非常诚实地暴露:你其实没说清楚。
这就是 Agent 最讨厌、也最有价值的地方。
它不吃默契,不懂眼色,不会因为怕得罪你而假装理解。你说「要有洞察」,它就给你写一段像洞察的废话。你说「要严谨」,它就多加几个免责声明。你说「主动推进」,它就开始自作主张。
错不全在模型。
你给它的本来就不是流程,是口号。
分界线
所以分界线很简单:
只改变语气的,是角色扮演。改变决策路径的,才是接口。

一段 Agent 规则有没有价值,不看它有没有「人格」,看它有没有改变这几件事:
它缺上下文时,是自己查、问人,还是停止?
它什么时候可以调用工具,什么时候必须先读文件,什么时候不能碰生产数据?
它判断一个结果好不好,依据是什么?
哪些风险必须拒绝,哪些只是提醒?
输出前必须过哪些质量闸?
失败时怎么处理:补证据、回滚、升级、重试,还是直接承认做不到?
过程能不能追踪?失败后能不能定位是输入错、规则错、工具错、模型错,还是验收标准错?
不一定每条规则都能做成布尔验收。但如果一条规则都验收不了、一处失败都追不回去,那就别急着说自己在做 Agent 工程。
写到这些,才开始像系统。
你不是在教 AI 成为某个人。
你是在把一个岗位拆成协议。
角色可以存在,但它最多是压缩标签。比如「严厉编辑」这四个字,可以帮助模型进入某种语气和关注点。
它能校准风格,不能替你做质量保证;能提醒模型看哪里,不能替你拦错;能让输出像编辑,不能让系统真的拥有编辑部的退稿机制。
如果后面没有「什么标题必须判废」「什么事实必须补证据」「什么表达看似有力但语义空」「什么情况下不能润色只能退回」,那这个严厉编辑只是一个脾气设定。
脾气不值钱。
能拦错的规则才值钱。
暗知识
公司里很多最值钱的东西,往往不在文档里。
主编知道什么标题一看就是软的。
老工程师知道什么改动闻起来会炸。
创始人知道什么客户不该接,哪怕对方预算看起来不错。
好 reviewer 知道什么问题是必须拦的风险,什么只是个人洁癖。
这些判断过去靠什么传?靠跟着老人干三个月,靠被骂两次,靠看别人怎么退稿,靠一次线上事故之后全组记住。
这套东西很值钱,但它不透明。新人学得慢,外包接不住,换个人风格就变,老人一走流程就塌。
你现在要让 Agent 做事,就必须把这些暗知识写出来。
我自己写 Agent 规则时,最卡的也不是 prompt 技巧。
是写到「什么标题必须退回」「什么事实必须补证据」「什么情况下不能润色只能停止」时,发现这些标准以前都只在脑子里。
机器不会继承我的默契,只会继承我写下来的规则。
这不是玄学。
管理学很早就把这类事叫 tacit knowledge 到 explicit knowledge 的转换。SECI 模型里,Externalization 讲的就是把隐性知识表达成显性知识,然后才能被分享和复用。
别被这个学术词吓到。放到 Agent 上,就是一句土话:
你得把「老手脑子里默认会做的事」写成「机器不会装懂也能执行的接口」。

这件事看起来像写 prompt,实际是在逼你承认:你以前很多流程根本没写过。
工程语言
你看真正做 Agent 工程的人在讨论什么,就知道这事离「人设」有多远。
Anthropic 那篇《Building effective agents》先区分 workflows 和 agents:workflows 是 LLM 和工具按预定义代码路径编排;agents 是 LLM 动态指导自己的流程和工具使用。它还提醒你从最简单方案开始,只有复杂度能明显改善结果时才加 agentic system,并强调透明度、工具文档、测试,以及把 ACI,也就是 Agent-计算机接口,像 HCI(人机交互)一样认真设计。
注意这些词:workflow、tools、transparency、testing、interface。
没有一个词叫「灵魂」。
OpenAI Agents SDK 也很直白:Agent 是带 instructions 和 tools 的 LLM;handoffs 处理委派;guardrails,也就是质量闸门 / 护栏,负责输入和输出校验;tracing,也就是过程追踪 / 可观测记录,用来可视化和调试流程。
instructions 只是一个部件,不是全部。
真正面向生产交付的关键词是工具、交接、闸门、追踪和评估。
这里不用把文档背一遍。只保留两个底线就够了:guardrails 不是一句「要严谨」,而是条件不满足时能阻断;tracing 不是玄学记录,而是把一次 run 里的模型输出、工具调用、交接、闸门和自定义事件留下来,方便 debug、visualize、monitor workflows。
这才是 Agent 和 cosplay 的分界线。
如果过程不可追踪,失败了你只能说「模型今天抽风」。
如果过程可追踪,你至少能问清楚:它是没读到输入,还是判断标准错了?是工具调用错了,还是闸门没拦住?是模型能力不够,还是你给的规则本来就是废话?
我自己的说法更刻薄一点:
对需要持续交付、持续改进的 Agent 系统来说,没有 trace 的调教,就是安抚神婆。没有 eval 的调教,就是跟一次满意输出谈恋爱。
evals,也就是评测集 / 评估机制,不是为了显得专业。
OpenAI Evals 的 README 说得很硬:没有 evals,就很难理解不同模型版本如何影响你的用例;高质量 evals 是构建 LLM 系统最有影响的事情之一。
这句话落到交付里就是:
别说你的 Agent 变好了。
先证明它错误更少、漏项更少、返工更少。
清单不幼稚
很多人反感 checklist,觉得那是低级流程。
这也是老毛病:把「专业」误解成「不需要明示步骤」。
外科手术 checklist 看起来也很幼稚:确认身份,确认部位,确认器械,确认关键节点。像小学生打勾。
但复杂系统里,高手也会漏步骤。专业不是把安全押在高手状态上,专业是知道哪里不能靠感觉。
AHRQ PSNet 收录的 Haynes 等人在 NEJM 发表的 WHO 手术安全 checklist 研究摘要里,19 项 checklist 覆盖 sign in、timeout、sign out 三个关键节点,摘要称实施后死亡率和住院并发症显著下降。
这不是说写 Agent 规则等于救命。
别乱拔高。
这里只说明一个朴素事实:显式检查点不是幼稚。它是复杂系统里对人类记忆、临场状态和组织默契的不信任。
好 Agent 的规则也是这个逻辑。
不是为了让模型「更像专家」。
是为了让它更少漏步骤,更少乱调用工具,更早暴露风险,更稳定地停在不能继续的地方。
「你要严谨」是人格要求。
「没有引用链接不得声称已核实」是质量闸门。
「你要主动」是团建标语。
「工具失败后必须换策略再查一次,仍失败才报告缺口」是失败接口。
「你要像架构师一样思考」是戏服。
「改数据库 migration 前先读 schema、调用点、回滚路径;没有测试覆盖不能交付」才是工程。
多 Agent
多 Agent 最容易骗人。
一个 Planner,一个 Executor,一个 Critic,一个 Researcher,一个 Manager,围成一桌互相点头。看起来像组织,实际连一个 checklist 都不如。
这里骂的不是所有多 Agent。
如果不同角色真的有不同工具权限、不同信息来源、不同否决权和验收责任,那就不是话剧社。名字不重要,信息差和权限差才重要。
我骂的是另一种东西:没有信息差异,没有权限差异,没有冲突解决,没有最终验收,没有失败归因。五个空角色互相复述一遍,产出的只是更长的 AI slop。
这不叫 agentic workflow。
这叫 AI 话剧社。
真正的多 Agent 不是「CEO Agent 发表愿景,CTO Agent 评估技术,CMO Agent 评估市场」。这套东西放在 X 上截图很好看,落到交付里基本是噪音。
真正有用的分工应该能回答:
谁能读什么输入?
谁能调用什么工具?
谁有权否决?
两个判断冲突时按什么规则合并?
最终交付前谁负责验收?
失败后 trace 指向谁的规则?
回答不了这些,就别装组织。
一个能拦错的 guardrail,比五个会开会的空角色值钱。
遮羞布
这也是为什么很多人写 Agent 写着写着会不舒服。
你以为你在调模型,结果你发现自己也说不清什么叫好。
你想写一个内容 Agent,结果卡在「什么选题值得写」。
你想写一个代码 Agent,结果卡在「什么改动算安全」。
你想写一个客服 Agent,结果卡在「什么客户需求该满足,什么该拒绝」。
你想写一个研究 Agent,结果卡在「查到什么程度算够,哪些来源有权重」。
这时候不要急着怪 prompt 技巧不够。
很多时候,是你自己的流程没成型。
人类工作里,这个缺口可以被关系和经验盖住。老板觉得不对,退回。老员工闻到风险,拦一下。客户不满意,临时救火。reviewer 觉得「怪怪的」,多问一句。
这些动作都是真的工作流。
只是以前没写出来。
Agent 把这个遮羞布扯掉了。
它问你:什么叫不对?什么叫风险?什么叫怪怪的?什么时候退回?谁来拦?拦下后怎么办?
你答不上来,它就只能演。
三问
所以判断一段 Agent 规训是不是过家家,不要看它写得像不像高手。
看三件事。
第一,能不能让另一个人照着做。
如果新人看了都执行不了,Agent 更别想稳定。人类还能靠语境补洞,模型只能在洞里胡编。
第二,能不能改变结果分布。
不是输出更像专家,而是错误更少、漏项更少、返工更少、该拒绝的时候更敢拒绝。语气变了不算,行为变了才算。
第三,能不能被追责和改进。
失败之后,你能不能定位问题:输入不完整,规则太松,工具说明烂,guardrail 没挡住,handoff 错了,还是 eval 根本没覆盖?
如果都不能,那就是 cosplay。
别用「Agent」这个词给它镀金。
戏服还是制度
我不反对你说 Agent 人设像过家家。
大部分确实像。
尤其是那种堆满「世界级」「顶级」「深度」「批判」「洞察」的 prompt,基本就是给模型穿西装。它不解决任何硬问题,只是让废话看起来更像专业人士写的。
但别把脏水泼到所有规则上。
给 Agent 立规矩,不等于迷信人设。
定义输入、工具、权限、流程、闸门、验收、trace、eval,这些不是角色扮演。这些是把原来靠老人脑补、靠临场感觉、靠组织默契兜底的东西,第一次写成可执行接口。
烂 Agent 才演专家。好 Agent 不像人。
它更像一条会执行、会停下、会暴露风险、能被调试的流程线。
所以最后的问题不是:调教 Agent 是不是角色扮演?
问题是:你写下来的到底是戏服,还是制度?
写戏服,就是 cosplay。
写制度,就是工程。
真正被调教的也不是 Agent。
是你那套以前只存在脑子里的流程。
【引用出处】
- 来源:Anthropic《Building effective agents》——workflows / agents 区分、从简单方案开始、透明度、工具文档、测试、ACI / HCI → https://www.anthropic.com/engineering/building-effective-agents
- 来源:OpenAI Agents SDK 文档——Agent、tools、handoffs、guardrails、tracing 等组成 → https://openai.github.io/openai-agents-python/
- 来源:OpenAI Agents SDK Guardrails 文档——guardrails 作为输入 / 输出 / 工具调用校验与阻断机制 → https://openai.github.io/openai-agents-python/guardrails/
- 来源:OpenAI Agents SDK Tracing 文档——tracing 记录 LLM generations、tool calls、handoffs、guardrails 和自定义事件,用于 debug / visualize / monitor workflows → https://openai.github.io/openai-agents-python/tracing/
- 来源:OpenAI Evals README——evals 对理解模型版本影响和构建 LLM 系统的重要性 → https://github.com/openai/evals
- 来源:AHRQ PSNet / Haynes et al. WHO surgical safety checklist 摘要——19 项 checklist、sign in / timeout / sign out 和死亡率、住院并发症下降 → https://psnet.ahrq.gov/issue/surgical-safety-checklist-reduce-morbidity-and-mortality-global-population
- 来源:ASCN SECI 模型页面——tacit knowledge 到 explicit knowledge、Externalization 的解释 → https://ascnhighered.org/ASCN/change_theories/collection/seci.html